Aizawa et al., Pattern Recognition 2026
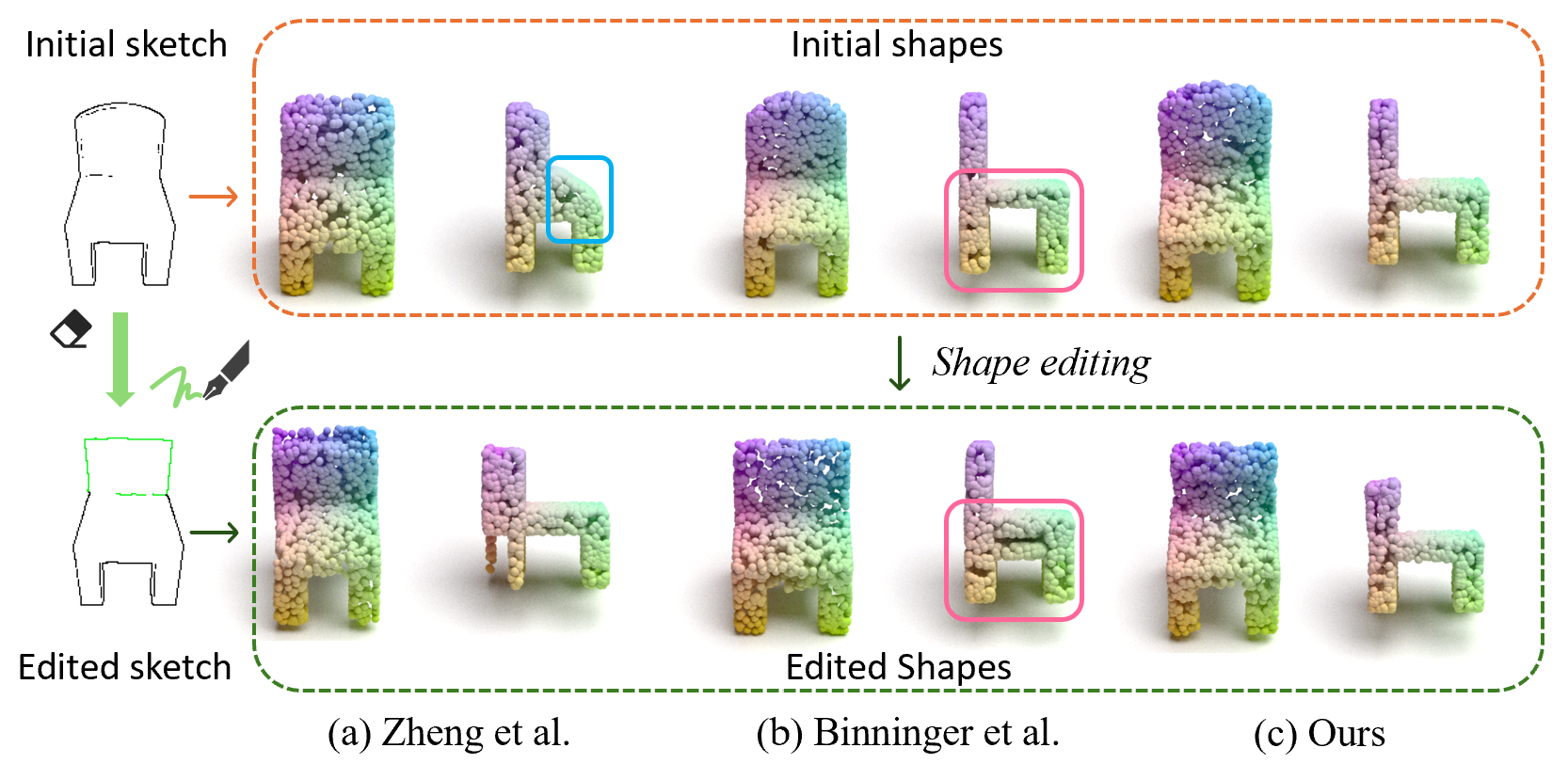
Towards Consistent Sketch-Guided Local 3D Shape Editing
Maeda et al., Pattern Recognition 2026
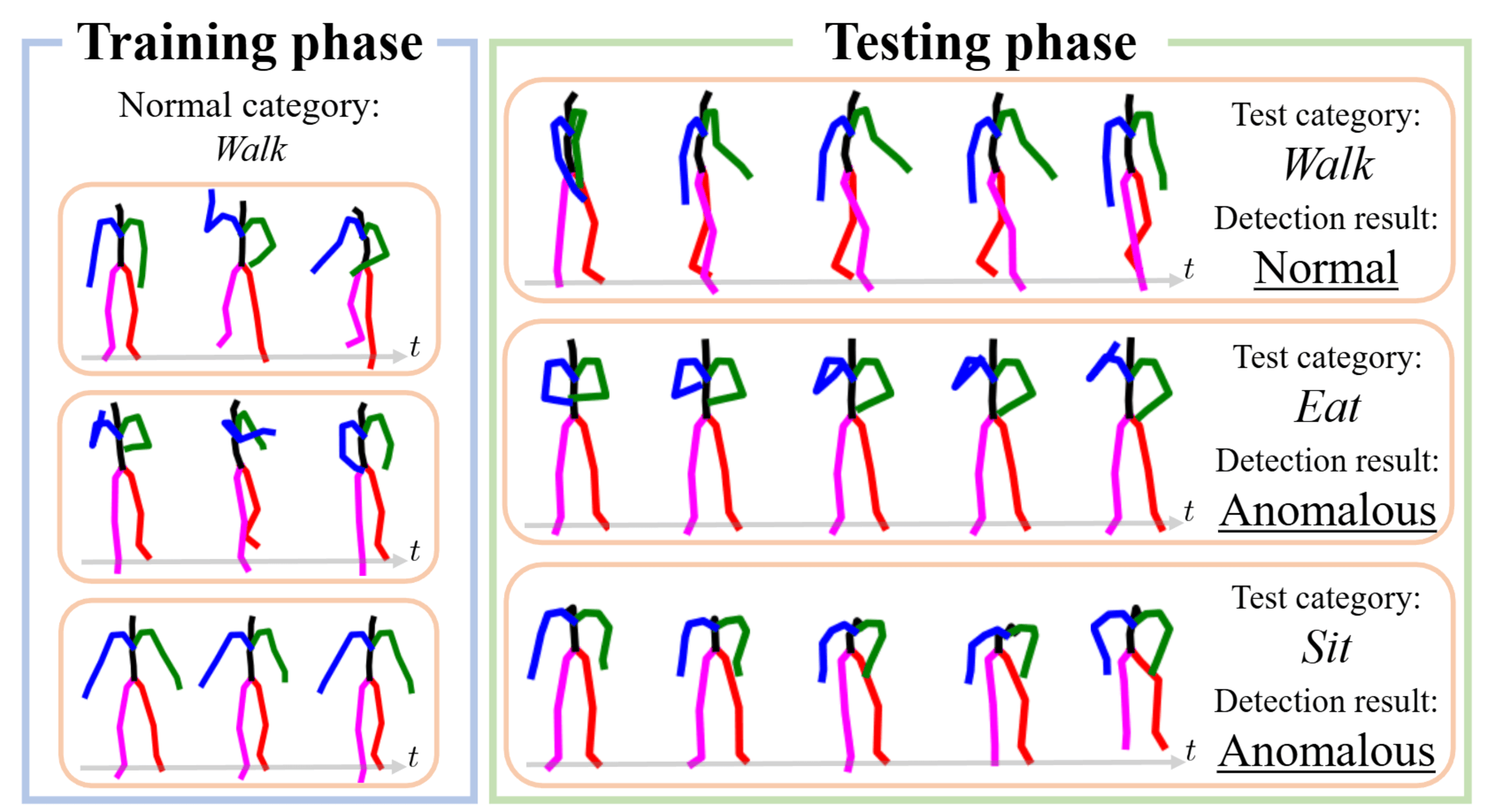
Frequency-Guided Multi-Level Human Action Anomaly Detection with Normalizing Flows
Gu et al., IEEE TVCG 2025
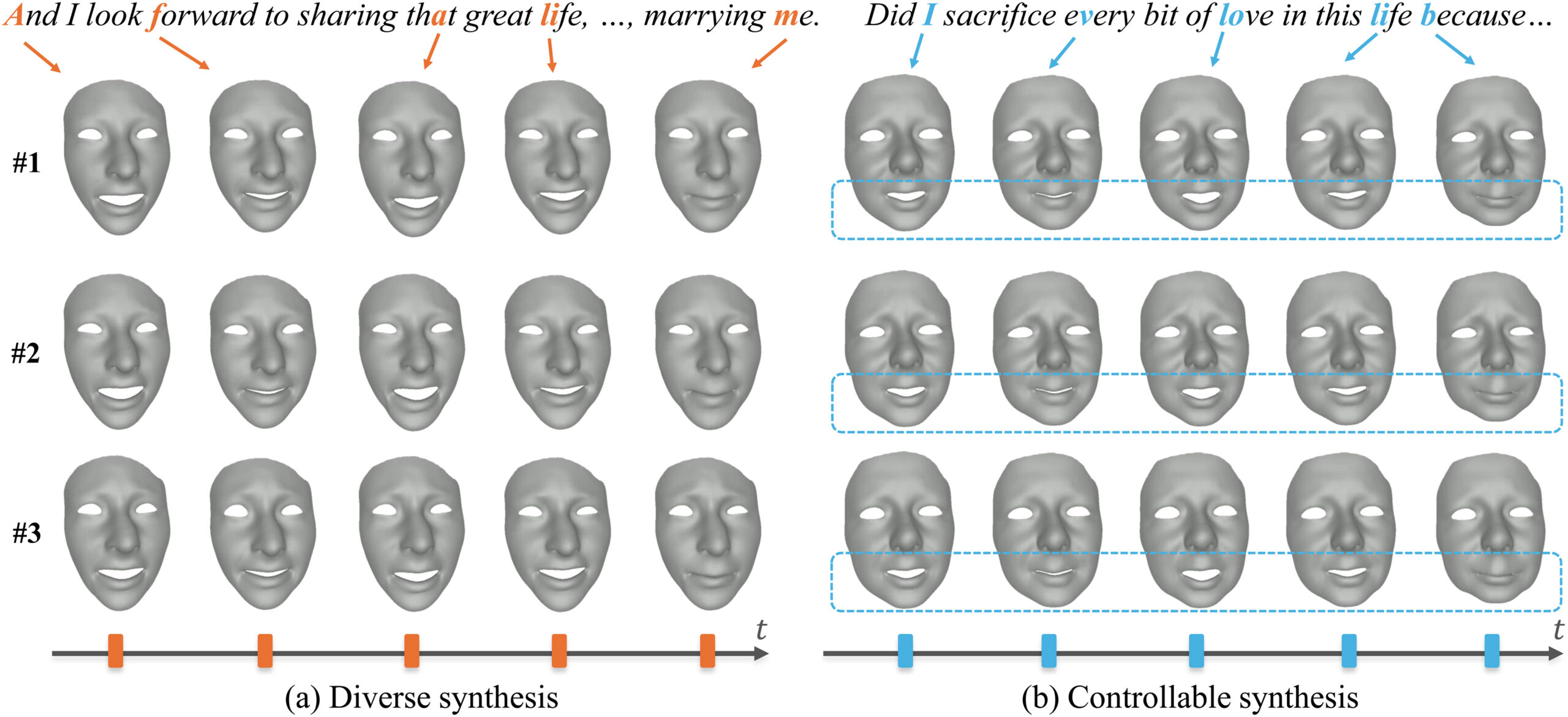
Diverse Code Query Learning for Speech-Driven Facial Animation
